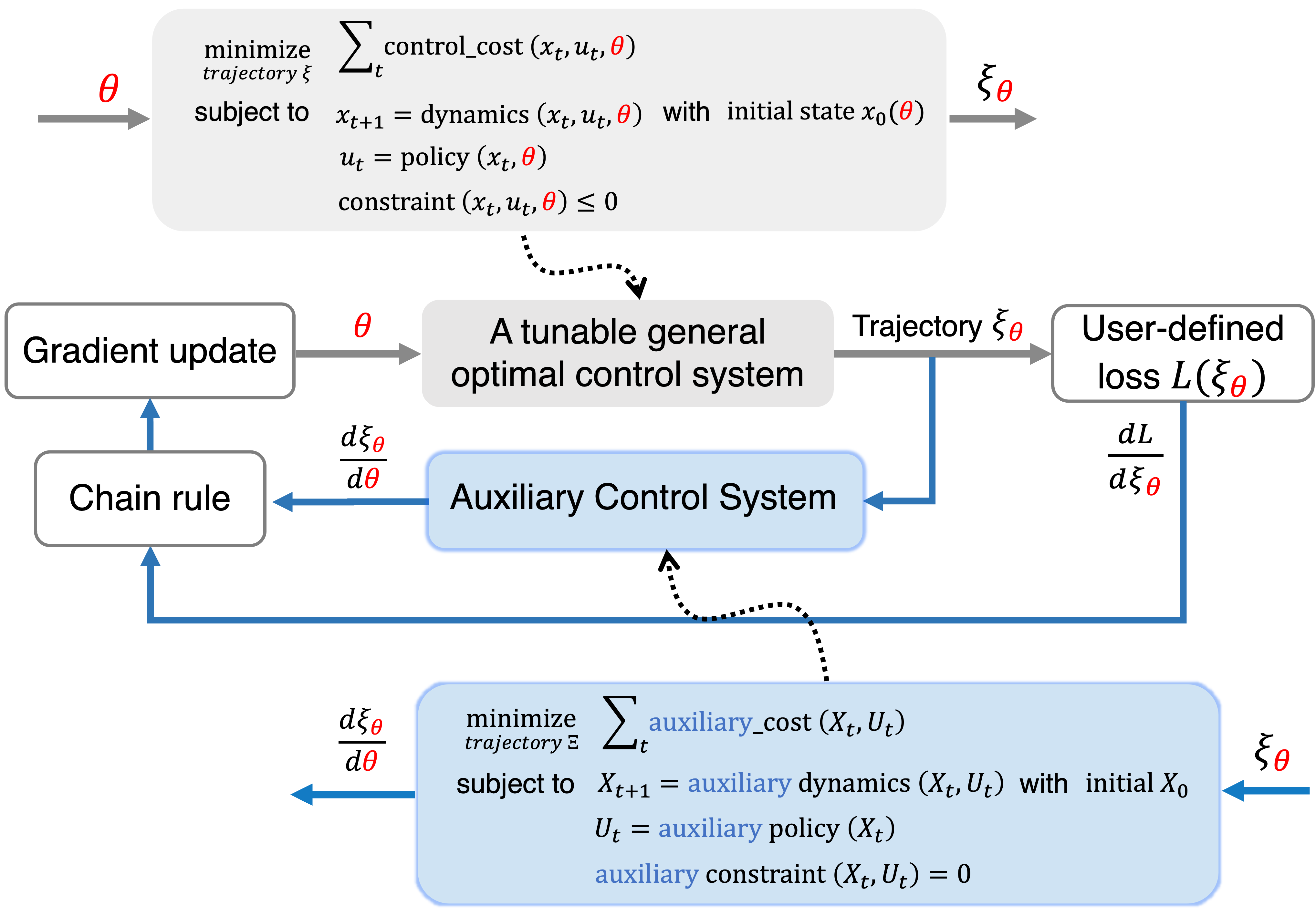
Overview: We devleoped a unified differentiable framework that is able to efficiently learn/auto-tune different components of a general optimal control system: (neural) cost/reward, (neural) dynamics ODE, (neural) policy, (neural) constraints, (neural) trajectory, (neural) initial conditions.
The overview of Pontryagin Differentiable Programming framework
Abstract
We developed the Pontryagin Differentiable Programming (PDP) methodology, which provides a unified differentiable solution to solve a broad class of learning and control tasks that can be formulated with a general optimal control system. The PDP features two new techniques: first, we proposed Differential Pontryagin's Maximum Principle, through which we can obtain the analytical derivative of a trajectory with respect to the tunable parameters in any components of the optimal control system, enabling auto-tuning dynamics ODE, policy, constraints, initial conditions, or/and cost/reward function; and second, we proposed the "Auxiliary Control System" in the backpropagation of the differentation path, and the trajectory of the Auxiliary Control System is exactly the analytical derivative of the original system's trajectory with respect to the parameters. This "Auxiliary Control System" makes the gradient computation through a optiaml control system more computationally efficient.
The PDP enables learning/auto-tuning different components in a general optimal control system: (neural) cost/reward, (neural) dynamics ODE, (neural) policy, (neural) constraints, (neural) trajectory, (neural) initial conditions.
1. PDP Formulation (abstract)
Consider a class of optimal control systems \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\), which are parameterized by a tunable parameter \(\textcolor{red}{\boldsymbol{\theta}}\) in its cost, dynamics ODE, initial condition, and constraints:
We here have parameterized all components in a general optimal control system \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\), for a specific application, one only needs to parameterize the unknown aspects and keep others given. Any unknown components in \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\) can be implemented by differentiable neural networks.
For a given \(\textcolor{red}{\boldsymbol{\theta}}\), \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\) produces a trajectory \(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}}\).
We aim to find/tune/learn a \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}^*})\), i.e, searching for a \(\textcolor{red}{\boldsymbol{\theta}^*}\), such that its trajectory \(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\boldsymbol{\theta}^*}}}\)
minimizes a design criterion \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\). Note that \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\) is given depending on the specific design task. The PDP problem can be formally written as:
\begin{equation}\label{equ_problem}
\begin{aligned}
\min_{\textcolor{red}{\boldsymbol{\theta}}} \quad &L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}}) \quad \\ \text{subject to}\quad &
\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}} \,\, \text{comes from $\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})$.}
\end{aligned}\tag*{PDP Problem}
\end{equation}
For a specific learning/control task, one only needs to specify details of \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\)
and give a loss \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\).
2. PDP Method
To solve the \ref{equ_problem}, we seeks to optimize the design loss \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\) using any gradient-based method, with the following update
\begin{equation}\label{GD}
\textcolor{red}{\boldsymbol{{\theta}}^+}=\textcolor{red}{\boldsymbol{{\theta}}}-\eta\frac{d L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})}{d \textcolor{red}{\boldsymbol{\theta}}} \quad \text{with (chain rule):}\quad \frac{d L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})}{d \textcolor{red}{\boldsymbol{\theta}}}=\frac{d L}{d \boldsymbol{{\xi}}_{\textcolor{red}{\boldsymbol{{\theta}}}}}\frac{d \boldsymbol{{\xi}}_{\textcolor{red}{\boldsymbol{{\theta}}}}}{d \textcolor{red}{\boldsymbol{{\theta}}}}
\end{equation}
Thus, in each update of \(\textcolor{red}{\boldsymbol{{\theta}}}\), the comptutation framework is drawn below
The main challenge is to how to do auto-differentiation to calculate \(\frac{d \boldsymbol{{\xi}}_{\textcolor{red}{\boldsymbol{{\theta}}}}}{d \textcolor{red}{\boldsymbol{{\theta}}}}\), i.e., the derivative of a trajectory with respect to the parameters in the general optimal control system.
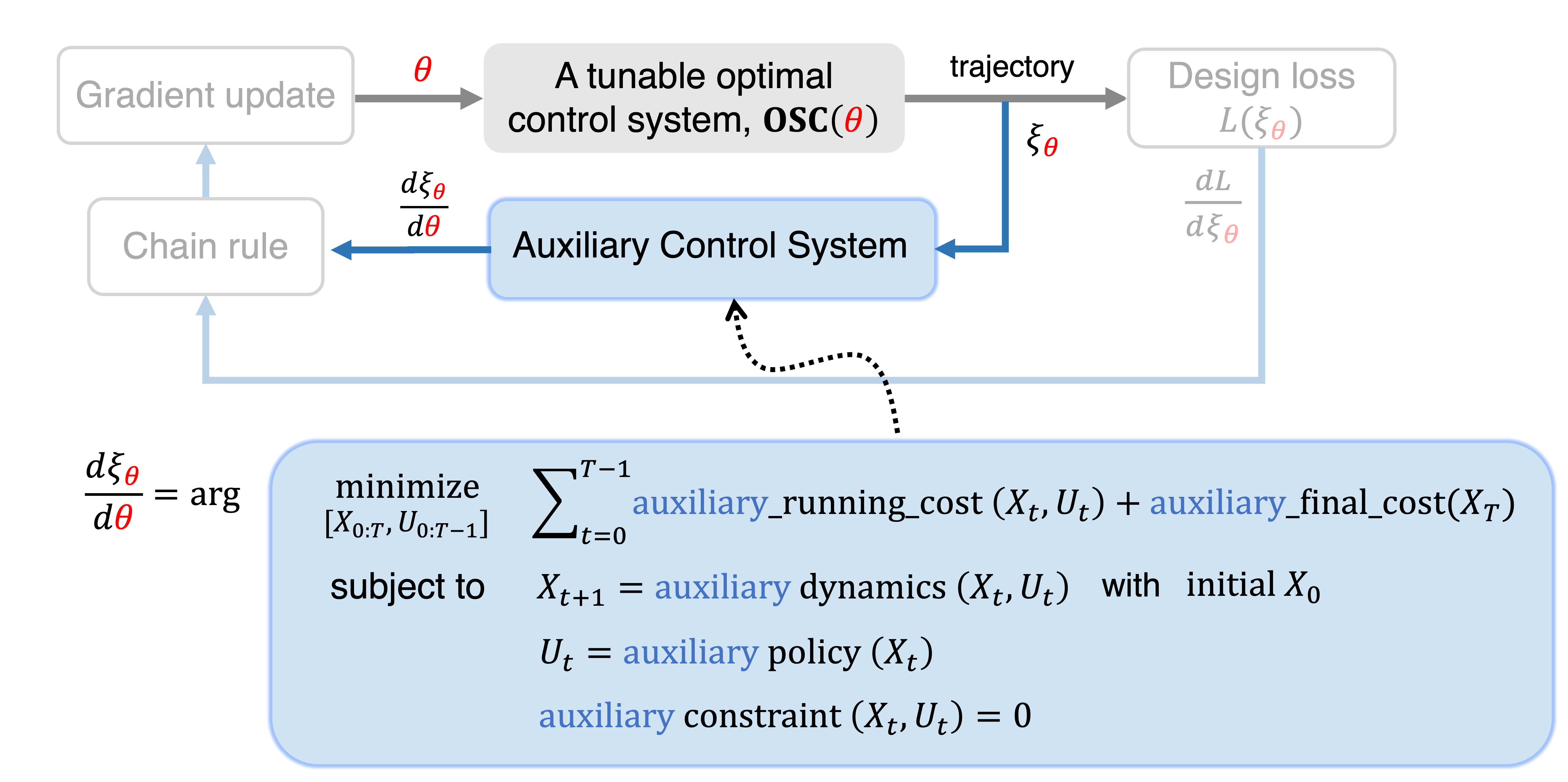
The key contributions of PDP are that we proposed the Differential Pontryagin's Maximum Principle (Differential PMP), based on which we invented the Auxiliary Control System, as a systematic tool to do the auto-differentiation. Specifically, Auxiliary Control System takes the original system's trajectory \(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}}\) and efficiently generates \(\frac{d \boldsymbol{{\xi}}_{\textcolor{red}{\boldsymbol{{\theta}}}}}{d \textcolor{red}{\boldsymbol{{\theta}}}}\). Below is the illustration to show how it looks like and works.
Takeaways 1: [Dual Structure]
The Auxiliary Control System is very easy to construct and possesses a dual structure for the original system. If the original system is optimal control system, then the Auxiliary Control System is a Linear Quadratic Regular (LQR); if the original system is feedback control system, then the corresponding Auxiliary Control System is also a feedback control system; if the original system is ODE (i.e. only including dynanmics), then the corresponding Auxiliary Control System is also a ODE.
Takeaways 2: [Existence and Unique Solution]
If the original system is differentiable (see the differentiablity condition in our papers), then Auxiliary Control System must exist and have a unique global solution.
Takeaways 3: [Working perfectly with Interior Point Methods]
The PDP including the Auxiliary Control System works seamlessly with Interior Point Methods [Potra, Florian A.; Stephen J. Wright. "Interior-point methods"]. Under the context of Interior-point method, we have proved that "the differentiablity of the relaxed optimal control system is guaranteed and continuous", i.e.,
\begin{equation}
\frac{d \boldsymbol{{\xi}}_{\textcolor{red}{\boldsymbol{{\theta}}}}(\textcolor{green}{\gamma})}{d \textcolor{red}{\boldsymbol{{\theta}}}}\rightarrow \frac{d \boldsymbol{{\xi}}_{\textcolor{red}{\boldsymbol{{\theta}}}}}{d \textcolor{red}{\boldsymbol{{\theta}}}}\quad \text{as} \quad \textcolor{green}{\gamma}\rightarrow 0
\end{equation}
where \(\textcolor{green}{\gamma}\) is the barrier penality parameter in the relaxed optimal control system (see more formal assertions in our papers)
3. Applications of PDP
Depending upon the details of \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\), i.e., what is unknown (thus parameterized), and the specific loss \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\), PDP can be used to solve various design/learning/planning problems. Here are a few simple examples.
3.1. Inverse Reinforcement Learning
Suppose we want to learn reward/cost from expert (optimal) demostrations. Thus, we parameterize the cost in \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\) and define \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\) to be the imitation loss. Then, the \ref{equ_problem} is a inverse reinforcement learning problem. Here are some demo results.
3.2. System Identification (Neural ODE)
Suppose that we want to learn or identify dynamics ODE from meansured input-state data of a black-box system. Thus, we parameterize the dynamics ODE in \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\) and define \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\) to be the supervised learning loss. Then, the \ref{equ_problem} is SysID (Neural ODE) problem. Here is one demo result.
3.3. Policy Optimization or Motion Planning (model-based)
Suppose that we want to find optimal policy (closed-loop) or plan (open loop) for a robotic system (assume the system dynamics has been identified above). Thus, in \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\) we parameterize the policy \(u_t=\pi(x_t,\textcolor{red}{\boldsymbol{\theta}})\) for policy optimization or trajectory \(u_t=\pi(t, \textcolor{red}{\boldsymbol{\theta}})\) for motion planning, and define \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\) to be reward or cost function. Then, the \ref{equ_problem} is to solve the policy optimization or motion planning problem. Here are some demo results.
3.4. Learning Constraints from Demonstrations
Suppose we want to design a MPC controller, where we don't know how to design the constraints. We can learn those constraints from the expert demonstration data. In particular, we parameterize the constraints in \(\textbf{OCS}(\textcolor{red}{\boldsymbol{\theta}})\) and define \(L(\boldsymbol{\xi}_{\textcolor{red}{\boldsymbol{\theta}}})\) to be the imitation loss. Then, the \ref{equ_problem} is a problem of learning constraints from demonstrations. Here is one demo result.
3.5. Learning from Sparse Demonstrations
As a novel application, in our T-RO paper, we have demonstrated how to use PDP to solve the problelm of learning from sparse demonstration.
4. Research Papers that directly use PDP
[1] Kun Cao, and Lihua Xie. "Trust-Region Inverse Reinforcement Learning." IEEE Transactions on Automatic Control, 2023.
[2] Ming Xu, Timothy L. Molloy, and Stephen Gould. "Revisiting Implicit Differentiation for Learning Problems in Optimal Control." Advances in Neural Information Processing Systems, 2023.
[3] Wanxin Jin, Todd Murphey, Dana Kulic, Neta Ezer, and Shaoshuai Mou. "Learning from sparse demonstrations." IEEE Transactions on Robotics, 2022.
[4] Kun Cao, and Lihua Xie. Game-Theoretic Inverse Reinforcement Learning: A Differential Pontryagin's Maximum Principle Approach. IEEE Transactions on Neural Networks and Learning Systems, 2022.
BibTeX
@article{jin2020pontryagin,
title={Pontryagin differentiable programming: An end-to-end learning and control framework},
author={Jin, Wanxin and Wang, Zhaoran and Yang, Zhuoran and Mou, Shaoshuai},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={7979--7992},
year={2020}
}
@article{jin2021safe,
title={Safe pontryagin differentiable programming},
author={Jin, Wanxin and Mou, Shaoshuai and Pappas, George J},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={16034--16050},
year={2021}
}