Table of Contents
- Task-Driven Hybrid Model Reduction for Dexterous Manipulation
- Learning from Human Directional Corrections
- Learning from Sparse Demonstrations
- Pontryagin Differentiable Programming: An End-to-End Learning and Control Framework
- Safe Pontryagin Differentiable Programming
Task-Driven Hybrid Model Reduction for Dexterous Manipulation
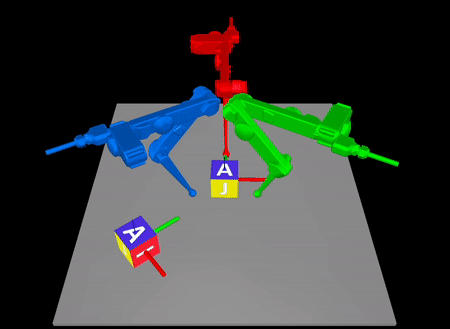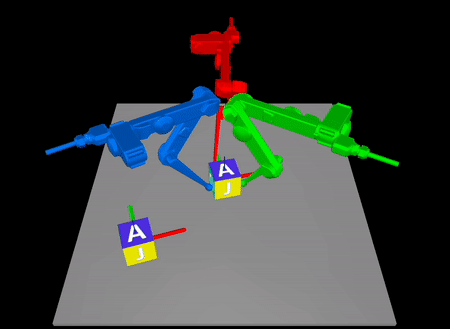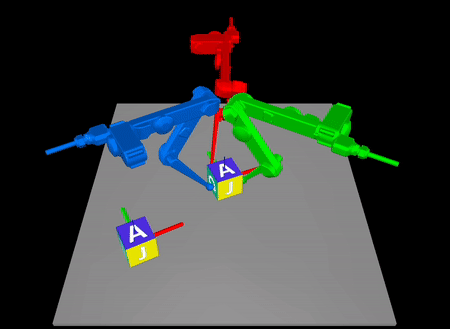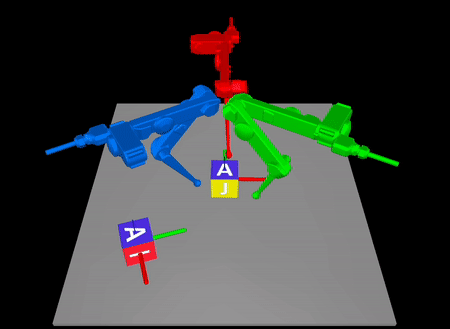
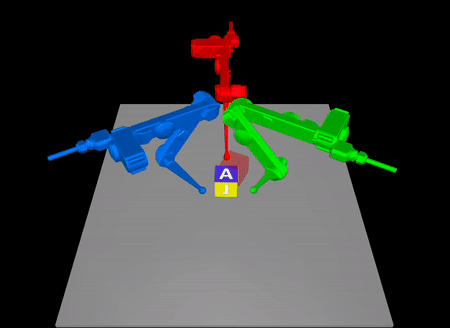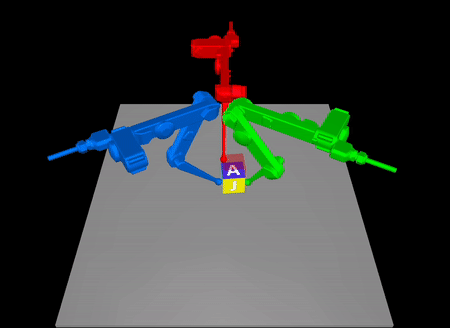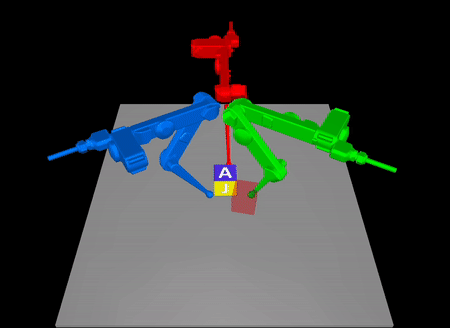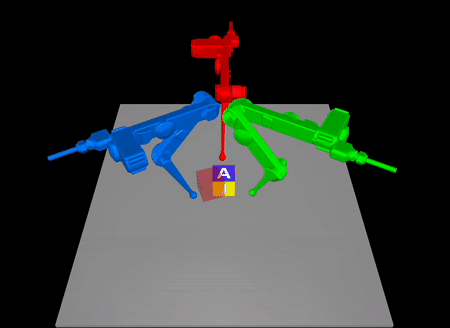
Arxiv: https://arxiv.org/abs/2211.16657
Code (Python): https://github.com/wanxinjin/Task-Driven-Hybrid-Reduction
Webpage: https://wanxinjin.github.io/td_hybridreduction/
Abstract (click to check abstract)
In contact-rich tasks, like dexterous manipulation, the hybrid nature of
making and breaking contact creates challenges for model representation and
control. For example, choosing and sequencing contact locations for in-hand
manipulation, where there are thousands of potential hybrid modes, is not
generally tractable. In this paper, we are inspired by the observation that far
fewer modes are actually necessary to accomplish many tasks. Building on our
prior work learning hybrid models, represented as linear complementarity
systems, we find a reduced-order hybrid model requiring only a limited number
of task-relevant modes. This simplified representation, in combination with
model predictive control, enables real-time control yet is sufficient for
achieving high performance. We demonstrate the proposed method first on
synthetic hybrid systems, reducing the mode count by multiple orders of
magnitude while achieving task performance loss of less than 5%. We also apply
the proposed method to a three-fingered robotic hand manipulating a previously
unknown object. With no prior knowledge, we achieve state-of-the-art
closed-loop performance in less than five minutes of online learning.
Learning from Human Directional Corrections
Arxiv: https://arxiv.org/abs/2011.15014
Code (Python): https://github.com/wanxinjin/Learning-from-Directional-Corrections
Abstract (click to check abstract)
This paper proposes a novel approach that enables a robot to learn an objective function incrementally from human directional corrections. Existing methods learn from human magnitude corrections; since a human needs to carefully choose the magnitude of each correction, those methods can easily lead to over-corrections and learning inefficiency. The proposed method only requires human directional corrections -- corrections that only indicate the direction of an input change without indicating its magnitude. We only assume that each correction, regardless of its magnitude, points in a direction that improves the robot's current motion relative to an unknown objective function. The allowable corrections satisfying this assumption account for half of the input space, as opposed to the magnitude corrections which have to lie in a shrinking level set. For each directional correction, the proposed method updates the estimate of the objective function based on a cutting plane method, which has a geometric interpretation. We have established theoretical results to show the convergence of the learning process. The proposed method has been tested in numerical examples, a user study on two human-robot games, and a real-world quadrotor experiment. The results confirm the convergence of the proposed method and further show that the method is significantly more effective (higher success rate), efficient/effortless (less human corrections needed), and potentially more accessible (fewer early wasted trials) than the state-of-the-art robot learning frameworks.
Learning from Sparse Demonstrations
Arxiv: https://arxiv.org/abs/2008.02159
Code (Python): https://github.com/wanxinjin/Learning-from-Sparse-Demonstrations
Abstract (click to check abstract)
This paper develops the method of Continuous Pontryagin Differentiable Programming (Continuous PDP), which enables a robot to learn an objective function from a few sparsely demonstrated keyframes. The keyframes, labeled with some time stamps, are the desired task-space outputs, which a robot is expected to follow sequentially. The time stamps of the keyframes can be different from the time of the robot's actual execution. The method jointly finds an objective function and a time-warping function such that the robot's resulting trajectory sequentially follows the keyframes with minimal discrepancy loss. The Continuous PDP minimizes the discrepancy loss using projected gradient descent, by efficiently solving the gradient of the robot trajectory with respect to the unknown parameters. The method is first evaluated on a simulated robot arm and then applied to a 6-DoF quadrotor to learn an objective function for motion planning in unmodeled environments. The results show the efficiency of the method, its ability to handle time misalignment between keyframes and robot execution, and the generalization of objective learning into unseen motion conditions.
Pontryagin Differentiable Programming: An End-to-End Learning and Control Framework
NeurIPS 2020 Presentation
Examples of using PDP to solve robotic tasks
Arxiv: https://arxiv.org/pdf/1912.12970
Code (Python): https://github.com/wanxinjin/Pontryagin-Differentiable-Programming
Abstract (click to check abstract)
This paper develops a Pontryagin Differentiable Programming (PDP) methodology,
which establishes a unified framework to solve a broad class of learning and control
tasks. The PDP distinguishes from existing methods by two novel techniques: first,
we differentiate through Pontryagin’s Maximum Principle, and this allows to obtain
the analytical derivative of a trajectory with respect to tunable parameters within an
optimal control system, enabling end-to-end learning of dynamics, policies, or/and
control objective functions; and second, we propose an auxiliary control system in
the backward pass of the PDP framework, and the output of this auxiliary control
system is the analytical derivative of the original system’s trajectory with respect
to the parameters, which can be iteratively solved using standard control tools. We
investigate three learning modes of the PDP: inverse reinforcement learning, system
identification, and control/planning. We demonstrate the capability of the PDP in
each learning mode on different high-dimensional systems, including multi-link
robot arm, 6-DoF maneuvering quadrotor, and 6-DoF rocket powered landing
Safe Pontryagin Differentiable Programming
NeurIPS 2021 Presentation
Examples of using Safe-PDP to solve safety-critical robotic tasks
Arxiv: https://arxiv.org/abs/2105.14937
Code (Python): https://github.com/wanxinjin/Safe-PDP
Abstract (click to check abstract)
We propose a Safe Pontryagin Differentiable Programming (Safe PDP) methodology, which establishes a theoretical and algorithmic framework to solve a broad class of safety-critical learning and control tasks -- problems that require the guarantee of safety constraint satisfaction at any stage of the learning and control progress. In the spirit of interior-point methods, Safe PDP handles different types of system constraints on states and inputs by incorporating them into the cost or loss through barrier functions. We prove three fundamentals of the proposed Safe PDP: first, both the solution and its gradient in the backward pass can be approximated by solving their more efficient unconstrained counterparts; second, the approximation for both the solution and its gradient can be controlled for arbitrary accuracy by a barrier parameter; and third, importantly, all intermediate results throughout the approximation and optimization strictly respect the constraints, thus guaranteeing safety throughout the entire learning and control process. We demonstrate the capabilities of Safe PDP in solving various safety-critical tasks, including safe policy optimization, safe motion planning, and learning MPCs from demonstrations, on different challenging systems such as 6-DoF maneuvering quadrotor and 6-DoF rocket powered landing.