Centralized Joint Control#
In the previous sections, we have discussed the design of independent joint controllers. These are based on a single input/single-output approach, and the coupling effects between the joints have been considered as disturbances acting on each single joint. When large operational speeds are required, or direct drive actuation is used \(\left(\boldsymbol{K}_{r}=\boldsymbol{I}\right)\), the nonlinear coupling terms strongly influence system performance. Thus, considering the effects of the components of \(\boldsymbol{d}\) as a disturbance may generate large tracking errors. In this case, it is advisable to design control algorithms that take advantage of a detailed knowledge of manipulator dynamics to compensate for the nonlinear coupling terms of the model. This leads to centralized control algorithms.
In the following control design for a \(n\)-joint manipulator, we consider a manipulator without external end-effector forces and any joint friction. The equation of motion of the manipulator thus is
The controller we want to design is in the general form of
i.e., the controller takes as input the manipulator’s current joint position \(\boldsymbol{q}\), current joint velocity \(\boldsymbol{\dot{q}}\), the desired joint position \(\boldsymbol{q}_d\), and desired joint velocity \(\boldsymbol{\dot{q}}_d\), and outputs the joint torque \(\boldsymbol{u}\).
Thus, the controlled manipulator with the controller is
Controller I: PD Control with Gravity Compensation#
Given a constant desired joint position \(\boldsymbol{q}_{d}\), we want to design a controller ([equ.controller]{reference-type=”ref” reference=”equ.controller”}), such that from any initial configuration, say \(\boldsymbol{q}_0\), the controlled manipulator ([equ.manipulator_control]{reference-type=”ref” reference=”equ.manipulator_control”}) will eventually reach \(\boldsymbol{q}_{d}\). If we define the joint space error as the error between the desired and the actual joint positions:
we want
Below, we will design the controller ([equ.controller]{reference-type=”ref” reference=”equ.controller”}) based on the Lyapunov method (see background of Lyapunov method in Lecture 16-17). First, we take the vector \(\begin{bmatrix}\boldsymbol{e}\\ \boldsymbol{\dot{q}}\end{bmatrix}\) as the control system state. Choose the following positive definite quadratic form as Lyapunov function candidate:
where \(\boldsymbol{K}_{P}\) is an \((n \times n)\) symmetric positive definite matrix. Differentiating \(V(\dot{\boldsymbol{q}}, {\boldsymbol{e}})\) with respect to time, and recalling that \(\boldsymbol{q}_{d}\) is constant, yields
From ([equ.manipulator]{reference-type=”ref” reference=”equ.manipulator”}), we can solve for \(\boldsymbol{B} \ddot{\boldsymbol{q}}\) and substituting it to the above equation gives
The first term on the right-hand side is zero since the matrix \(\boldsymbol{N}=\dot{\boldsymbol{B}}-2 \boldsymbol{C}\) is a skew-symmetric matrix (see in the property of dynamics in Lecture 18). For the second term to be negative definite, we can take the controller ([equ.controller]{reference-type=”ref” reference=”equ.controller”}) as the follows:
Important
with \(\boldsymbol{K}_{D}\) positive definite, corresponding to a nonlinear compensation action of gravitational terms with a linear proportional-derivative (PD) action.
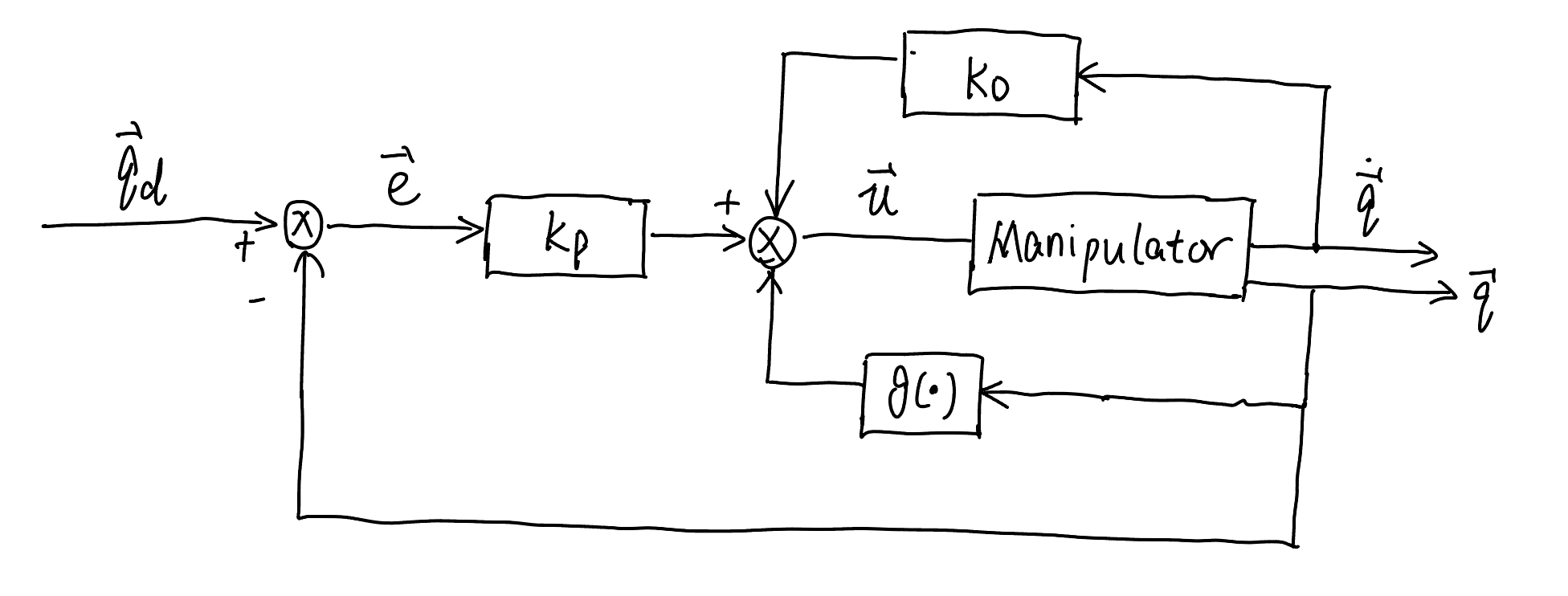
Fig. 80 Control diagram of PD control with gravity compensation#
With the above controller ([equ.controller2]{reference-type=”ref” reference=”equ.controller2”}), the time derivative of the Lyapunov function in ([equ.lypuanovdot]{reference-type=”ref” reference=”equ.lypuanovdot”}) becomes
and thus, \(V\) decreases long as \(\dot{\boldsymbol{q}} \neq \mathbf{0}\) for all system trajectories. Thus, the controller manipulator will reach an equilibrium configuration, with condition \(\dot{V}= 0\) and \(\dot{\boldsymbol{q}}=\mathbf{0}\). To find the equilibrium configuration, we look at the manipulator dynamics under control
With the condition \(\dot{\boldsymbol{q}}=\mathbf{0}\), it follows that \(\ddot{\boldsymbol{q}} =\mathbf{0}\), and then from the above dynamics, we have
Therefore, the manipulator will eventually reach equilibrium, which is exactly the desired configuration \(\boldsymbol{q}_{d}\).
The above derivation rigorously shows that any manipulator equilibrium posture is globally asymptotically stable under a controller with a PD linear action and a nonlinear gravity compensating action. Stability is ensured for any choice of \(\boldsymbol{K}_{P}\) and \(\boldsymbol{K}_{D}\), as long as these are positive definite matrices. The control law requires the on-line computation of the term \(\boldsymbol{g}(\boldsymbol{q})\).
Controller II: Inverse Dynamics Control#
One limitation of the above controller is that the above controller can only follow a stationary desired \(\boldsymbol{q}_d\), but is not good at tracking a changing desired joint signal: i.e.,
The approach of inverse dynamics control is trying to address the above limitation. The idea of inverse dynamics control is to find a controller ([equ.controller]{reference-type=”ref” reference=”equ.controller”}) that can directly lead to linearization of system dynamics. To do so, we set the controller ([equ.controller]{reference-type=”ref” reference=”equ.controller”}) in the following particular form:
Important
where \(\boldsymbol{y}\) is a new input vector whose expression is to be determined yet. The above controller directly leads to the controlled manipulator ([equ.manipulator_control]{reference-type=”ref” reference=”equ.manipulator_control”}) as
leading to
Again, we will discuss how to set this new control input vector \(\boldsymbol{y}\), but the particular form of controller ([equ:u]{reference-type=”ref” reference=”equ:u”}) leads to a linear relationship between the input signal \(\boldsymbol{y}\) and the manipulator’s joint acceleration \(\ddot{\boldsymbol{q}}\).
The control diagram corresponding to the controller ([equ:u]{reference-type=”ref” reference=”equ:u”}) is shown in Fig. 2{reference-type=”ref” reference=”fig:2”}. The controller ([equ:u]{reference-type=”ref” reference=”equ:u”}) is termed inverse dynamics control as it is based on the computation of inverse dynamics. From ([equ.dyn_new]{reference-type=”ref” reference=”equ.dyn_new”}, the controlled manipulator system is linear and decoupled with respect to new input \(\boldsymbol{y}\).
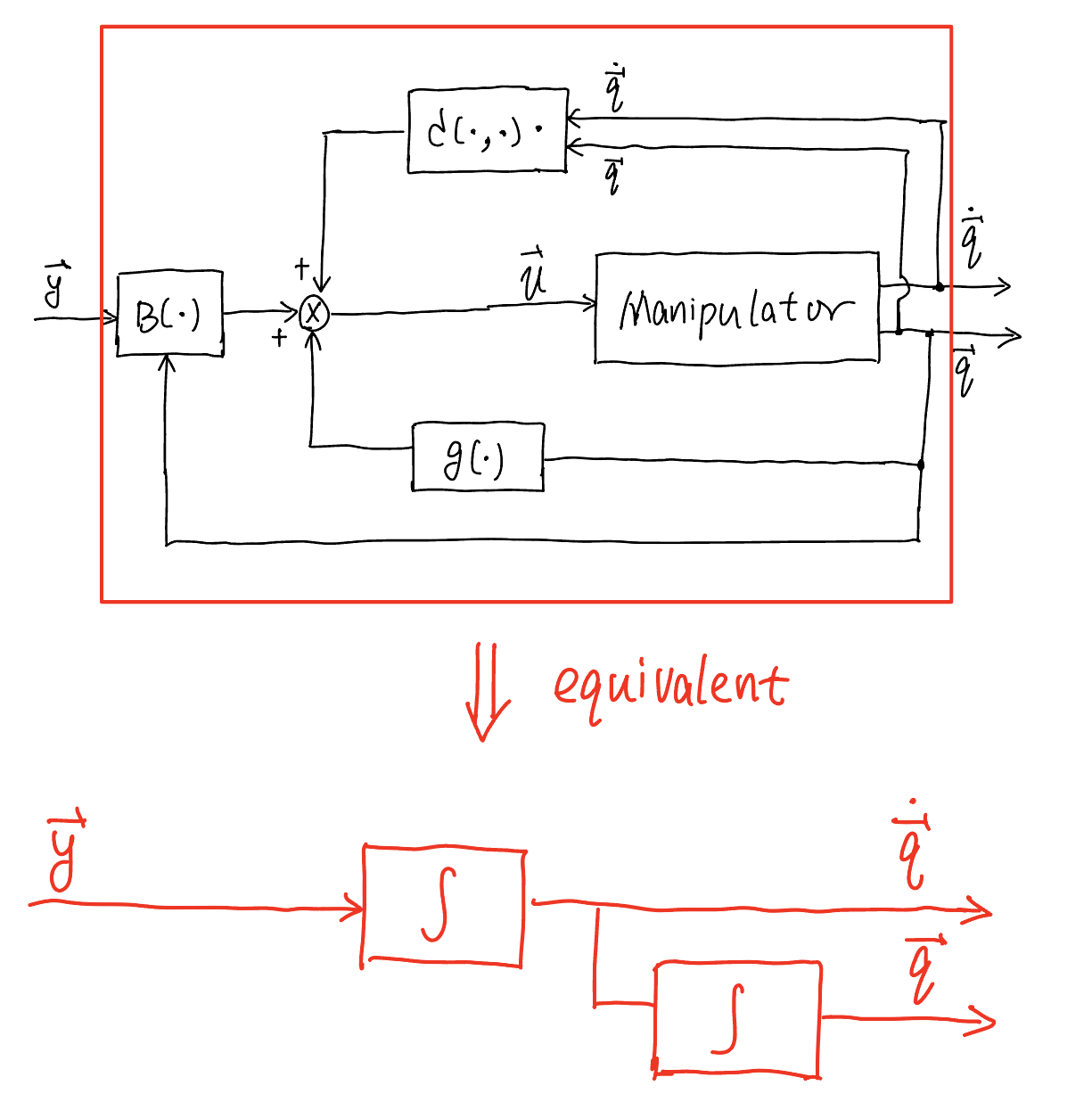
Fig. 81 Exact linearization performed by inverse dynamics control#
Thus, the manipulator control problem is reduced to that of finding a control input signal \(\boldsymbol{y}\). To this end,
Important
Here, \(\boldsymbol{K}_{P}\) and \(\boldsymbol{K}_{D}\) are positive definite matrices. Plugging the above \(\boldsymbol{y}\) signal into ([equ.dyn_new]{reference-type=”ref” reference=”equ.dyn_new”}) leads to
Again, if we define the error \(\boldsymbol{e}={\boldsymbol{q}}_{d}-{\boldsymbol{q}}\), the above ([equ.error_dyn]{reference-type=”ref” reference=”equ.error_dyn”}) becomes the following error dynamics
expressing the dynamics of position error while tracking the given trajectory. This is a standard second-order error system, where its convergence depends on the value of \(\boldsymbol{K}_P\) and \(\boldsymbol{K}_D\). Particularly, we usually choose
Then, the controlled manipulator dynamics is replaced with \(n\) linear and decoupled second-order subsystems. For each joint \(i\), please see my control background notes for how the values of the damping ratio \(\zeta_i\) and natural frequency \(\omega_{ni}\) can affect the trajectory of \(\boldsymbol{e}(t)\).
The resulting block scheme is illustrated in Fig. 3{reference-type=”ref” reference=”fig:3”}. Notice that the inverse dynamics controller requires computation of the inertia matrix \(\boldsymbol{B}(\boldsymbol{q})\), \(\boldsymbol{C}(\boldsymbol{q}, \dot{\boldsymbol{q}})\), and \(\boldsymbol{g}(\boldsymbol{q})\). Nonetheless, this technique is based on the assumption of perfect cancellation of dynamic terms, and then it is quite natural to raise questions about sensitivity and robustness problems due to unavoidably imperfect compensation.
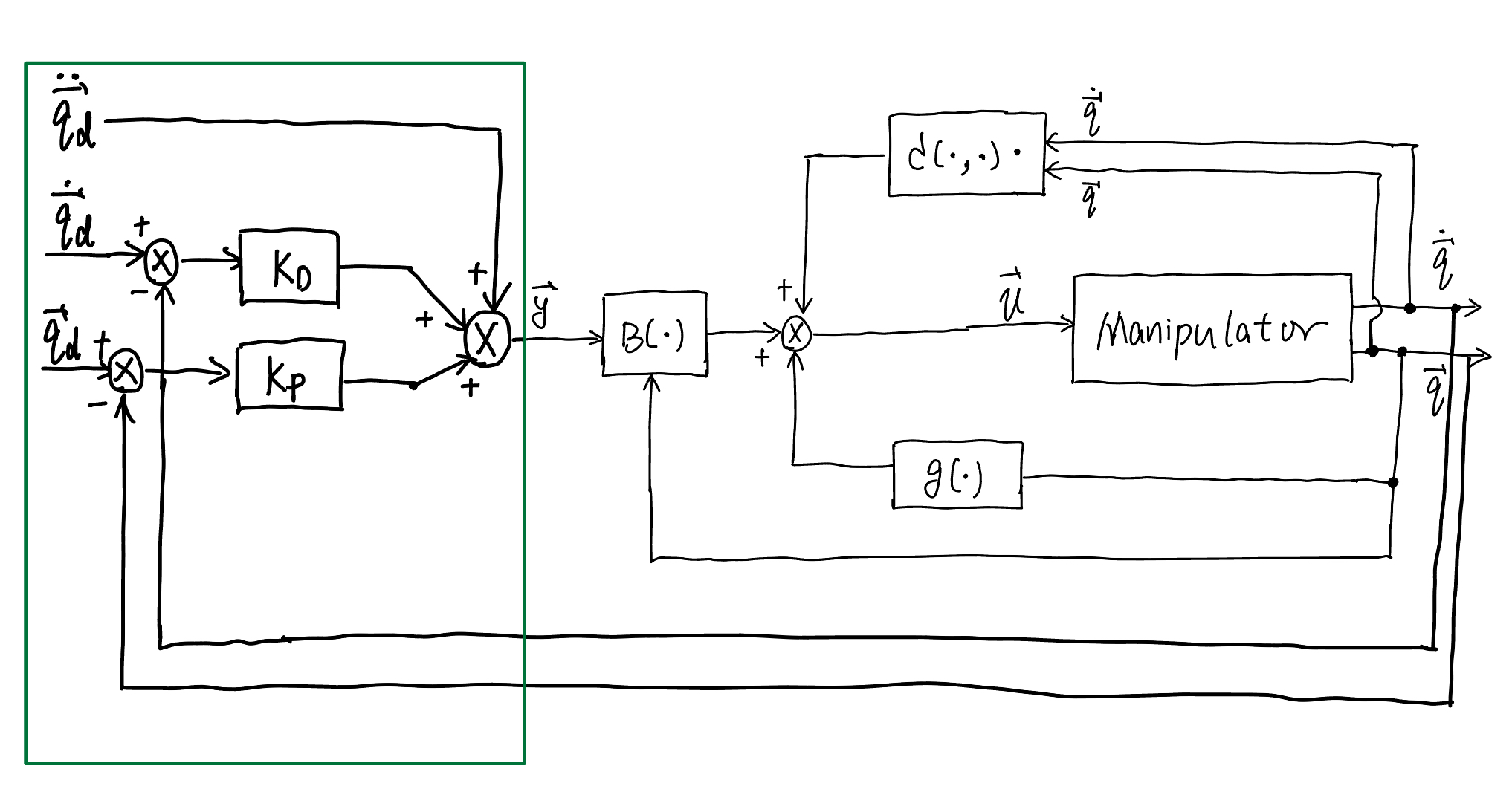
Fig. 82 Control diagram of joint space inverse dynamics control#